コンピューターの画面上では同じ「1文字」に見えるのに、システム上のサイズは同じにならないことがあります。 たとえば、英字の A と日本語の あ は、見た目としてはどちらも1文字です。 しかし UTF-8 で保存したときのバイト数は、A が1バイト、あ が3バイトになります。
この違いを考えるときに出てくるのが、エンコードとバイト数です。
文字はそのまま保存されているわけではない
コンピューターが直接扱うのは、文字そのものではなく数値やバイトの並びです。 私たちが画面で見ている「文字」は、人間が読みやすい形に表示された結果です。
文字を保存したり送ったりするときは、まず文字をコンピューターが扱える形に変換します。 この変換のルールがエンコードです。
たとえば「こんにちは」という文字列を保存するとき、コンピューターの中では「こ」「ん」「に」「ち」「は」という見た目の文字がそのまま置かれているわけではありません。 それぞれの文字を、決められた方式に従ってバイト列へ変換しています。
バイト数は文字列の実際の大きさに近い
バイト数は、文字列をデータとして扱うときの大きさを考えるための単位です。 ファイルサイズ、通信量、データベースの保存容量、API の入力制限などでは、見た目の文字数ではなくバイト数が問題になることがあります。
日本語を含むテキストでは、文字数とバイト数が大きくずれることがあります。 英数字だけの文章ではほぼ文字数と近い値になっても、日本語、絵文字、記号を含むと、バイト数は一気に増えます。
UTF-8、UTF-16、UTF-32で何が違うのか
UTF-8、UTF-16、UTF-32 は、Unicode の文字をバイト列として表すための方式で、同じ文字であったとしても、どの方式で表すかによって必要なバイト数が変わります。
UTF-8は、英数字を1バイトで表せる一方、日本語や絵文字では複数バイトを使います。 Webや多くのテキストファイルでは UTF-8がもっとも広く使われているようですね。
UTF-16は、多くの文字を2バイト単位で扱います。 ただし、絵文字など一部の文字は4バイトになることがあります。
UTF-32は、基本的に4バイトで扱います。 仕組みとしては分かりやすい一方、データ量は大きくなりやすい方式です。
文字数とバイト数は別のもの
文字数は、人間が読む文章の長さを確認するための値です。 一方でバイト数は、その文章をデータとして保存したり送信したりするときの大きさを確認するための値です。
また、文字数にもいくつかの数え方があります。 たとえば、絵文字や濁点付き文字、複数の記号を組み合わせた文字は、見た目の1文字と内部的な単位が一致しないことがあります。
どんなときに確認するとよいか
バイト数は、次のような場面で確認しておくと役に立ちます。
- 入力欄やCSV項目にバイト数制限があるとき
- APIに送る文字列のサイズを見たいとき
- 日本語や絵文字を含む文章が想定より大きくなっていないか確認したいとき
- UTF-8、UTF-16、UTF-32 でサイズがどう変わるか見たいとき
文字数だけを見ていると、データとしての大きさは分かりません。 逆に、バイト数だけを見ていると、文章としての長さや読みやすさは分かりません。
文章を人間が読むものとして見るのか、システムが扱うデータとして見るのか。 その違いを切り分けるために、文字数とバイト数を分けて確認できるようにしておくと便利です。
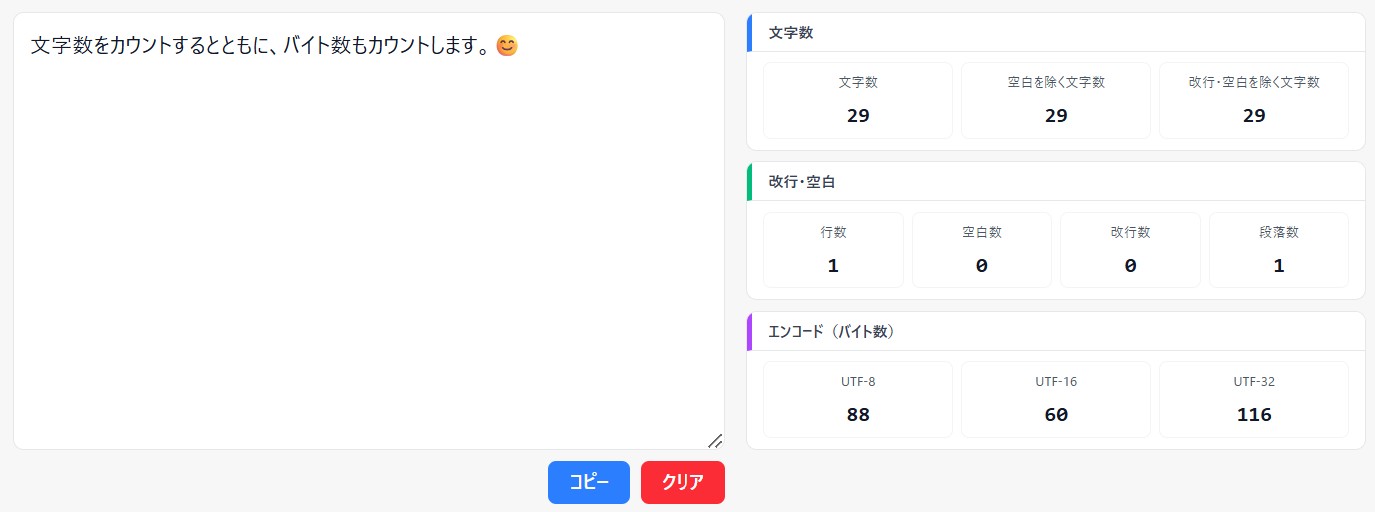
tojihubでは、「文字数カウンター」というツールを公開しており、文字数のほか、バイト数のカウントが可能です。