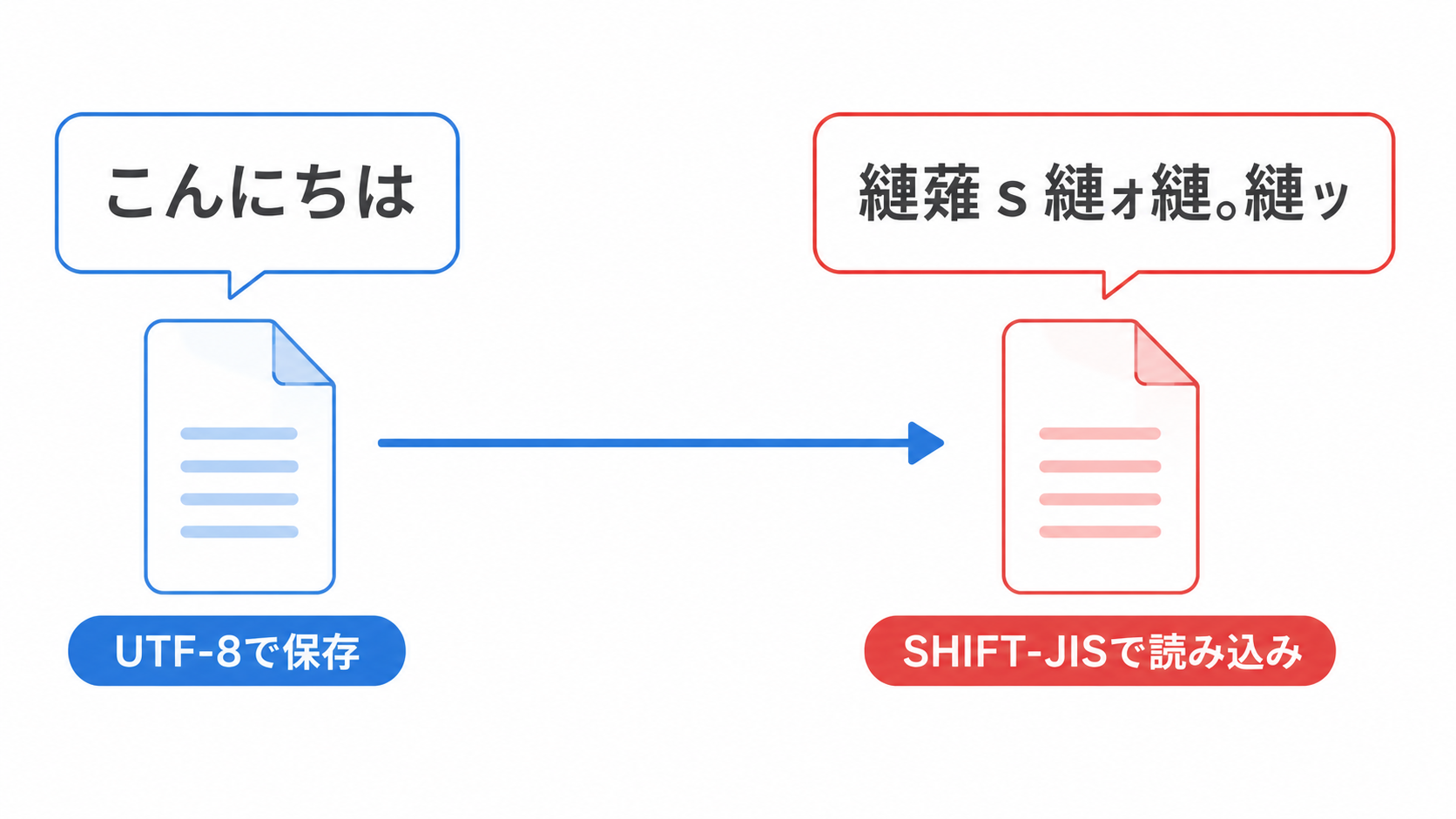
文字化けは、コンピュータ上で文字が壊れたように見える現象です。 日本語の文章が「縺薙s縺ォ縺。縺ッ」のように表示されたり、「�」が混ざったり、意味のない記号の並びになったりします。
文字そのものが急に壊れたように見えますが、多くの場合、原因は文字をバイト列として読むときのルール違いです。 保存したときのエンコードと、読み込むときに使ったエンコードがずれると、元の文字とは違うものとして解釈されます。
文字コードとエンコードは何が違うのか
文字コードという言葉は、少し広く使われます。 日常的には UTF-8 や Shift_JIS のような方式をまとめて「文字コード」と呼ぶこともあります。
もう少し分けて考えると、まず文字に番号を割り当てる考え方があります。 Unicodeでは、それぞれの文字にコードポイントという U+3042 のような番号が割り当てられています。
一方で、エンコードは、その番号や文字を実際のバイト列として表すための方式です。 UTF-8、UTF-16、Shift_JIS、EUC-JP、ISO-2022-JPなどは、文字をバイトに変換したり、バイトから文字へ戻したりするためのルールです。
保存するときと読むときでルールがずれると文字化けする
文字列をファイルに保存するとき、文字はエンコードされてバイト列になります。 そのファイルを開くとき、アプリケーションは何らかのルールに基づいて、エンコードされたバイト列を文字列として読み直します。
このとき、保存時と読み込み時のルールが一致していれば、元の文字列に戻ります。
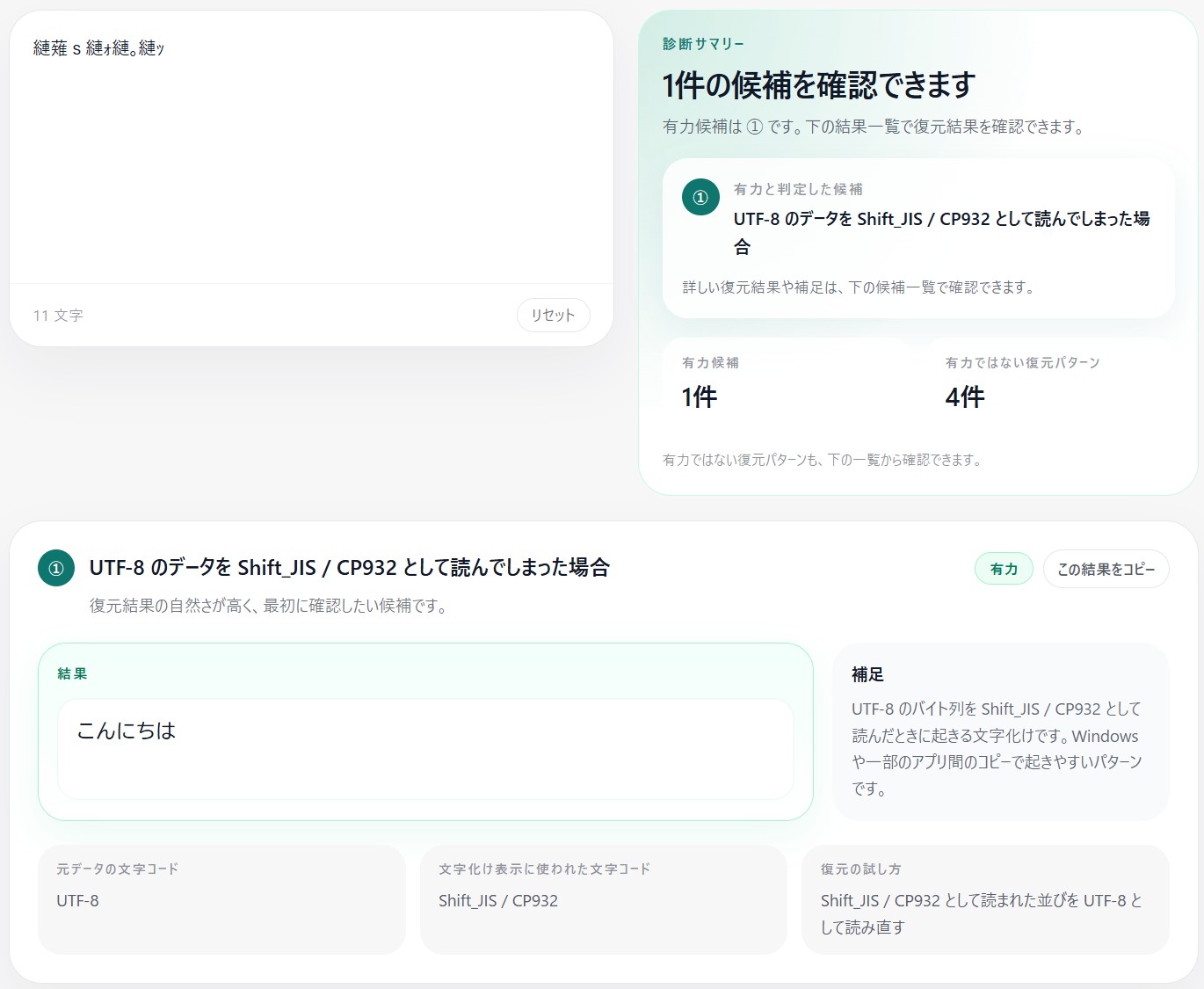
しかし、UTF-8 で保存された日本語を Shift_JIS / CP932 として読んでしまうと、まったく違う文字列として表示されることがあります。
また、例えばShift_JIS / CP932 のデータを UTF-8 として読んでしまうと、欠損文字の � が混ざることがあります。 これは、元のバイト列が UTF-8 として有効な並びではないため、読み取り側が「ここは正しく解釈できなかった」と置き換えて表示している状態です。
よくある文字化けのパターン
たとえば「こんにちは」が「縺薙s縺ォ縺。縺ッ」のように見える場合は、UTF-8 の日本語を Shift_JIS / CP932 として読んだときの典型的な形に近いです。
英語や記号を含む文章では、UTF-8 のデータを Windows-1252 / Latin-1 として読んだ結果として、Café が Café のように見えることがあります。
復元できる場合と難しい場合がある
文字化けは、いつでも完全に直せるわけではありません。 元のバイト情報が残っていれば、別のエンコードとして読み直すことで復元できることがあります。
一方で、読み取り時に � や ? に置き換えられてしまった場合、元のバイトの一部が失われていることがあります。 この場合は、候補を出せても元の文字列を確定するのは難しくなります。
そのため、文字化けを見つけたときは、化けた後の文字列だけを直そうとするより、元のファイルや元のデータをどのエンコードで開くべきだったのかを確認する方が近道になることがあります。
文字化けしたときに確認したいこと
文字化けに遭遇したら、まず次の点を確認すると原因を絞り込みやすくなります。
- 元のファイルはどこから来たものか
- CSV、メール、HTML、ログなど、どの形式のデータか
- 作成元のシステムやアプリが古くないか
- UTF-8、Shift_JIS / CP932、EUC-JP など、想定されるエンコードがあるか
�が大量に出ているか、読めそうな別文字に化けているか
文字化けは、見た目だけでは原因を決めきれないことがあります。 ただし、どのエンコードで保存され、どのエンコードとして読まれたのかを分けて考えると、確認する順番はかなり整理できます。
tojihubでは、「文字化け診断・復元」というツールを公開しており、文字化けのパターン診断と復元が可能です。
� や ? に置き換えられてしまった場合など、復元が難しいパターンの場合は、復元できないことを明示しています。