康熙部首(こうきぶしゅ)は、Unicode に収録されている部首専用の文字です。 見た目は通常の漢字とほとんど同じでも、文字コードとしては別の文字として扱われます。
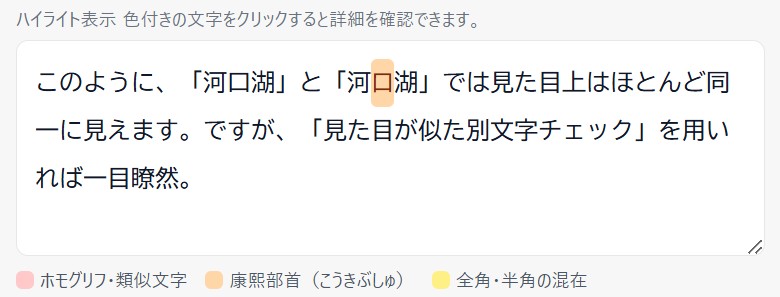
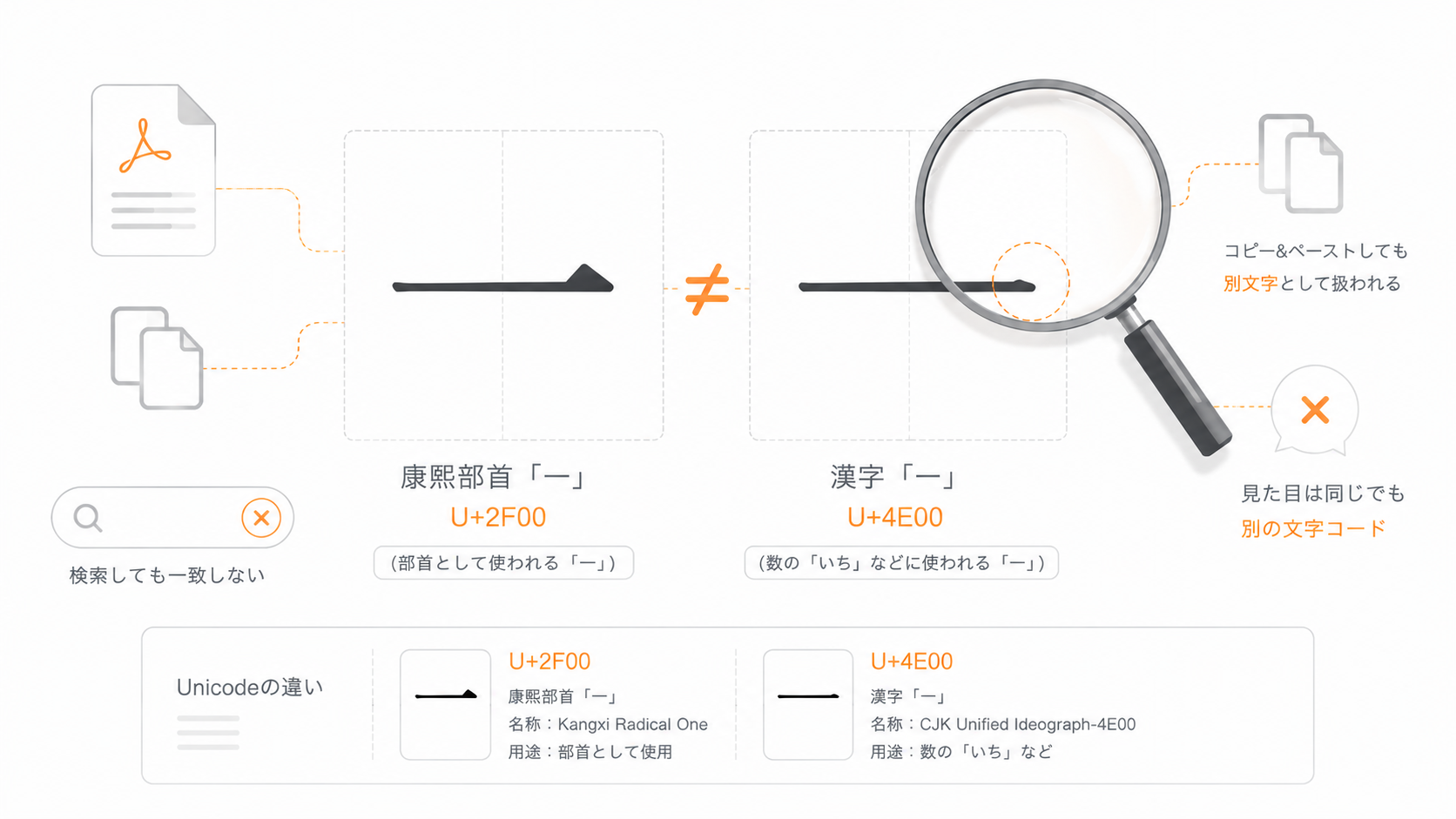
たとえば、通常の漢字としての「口」(くち)と、康熙部首としての「⼝」を見比べるとどうでしょうか?見た目だけでは区別しづらいですが、確かに文字コードは異なっています。 コンピューター上の処理では文字コードに基づいて、同一の文字であるかどうかを判定しているため、見た目がどれだけ似ていても、検索・置換・プログラム上の比較では別物として扱われます。
康熙部首は何のための文字か
康熙部首は、漢字の部首そのものを表すために用意された文字です。 通常の文章を書くための漢字とは目的が少し違います。
問題になるのは、部首として使うための文字が、普通の文章やデータの中に混ざってしまう場合です。 画面上では同じ漢字に見えるため、目視では気づきにくいです。
紛れ込みやすい場面
康熙部首は、次のような場面で紛れ込むことがあります。
- WebページやPDFから文字をコピーしたとき
- 辞書、教材、漢字表、文字表からコピーしたとき
- OCRで読み取った文字をそのまま使ったとき
- 外部サービスから出力されたCSVやExcelを取り込んだとき
- 文字を自動変換する処理を挟んだとき
普通の文章ではほとんど意識しない文字ですが、データ処理では「見た目が同じなのに一致しない」という形で問題になることがあります。
困るのは目で見ても分かりにくいこと
康熙部首が混ざっていると、検索しても見つからない、同じ値のはずなのに一致しない、置換したつもりなのに一部だけ残る、といったことが起きます。
みなと(この記事の著者)は、あるシステムで特定の文字が文字化けして表示され、検索にも引っかからないという場面で、康熙部首に悩まされたことがあります。 元の文字列はPDFからコピーしたもので、コピーした文字の中に康熙部首が含まれていたことが原因でした。
PDFに康熙部首が混ざった経緯までは分かりません。 ただ、コピー先のシステム側では康熙部首の文字を想定通りに扱えず、表示上は文字化けのように見え、検索機能でも期待した結果が返ってきませんでした。
この手の問題がややこしいのは、見た目では「普通の漢字」に見えることです。 人間が読む分には同じに見えても、システムから見ると別の文字です。 そのため、通常の漢字で検索しても、康熙部首として入っている文字には一致しません。
最終的には、康熙部首に該当する文字コードを入力禁止文字として扱うことで、同じ問題が再発しないようにしました。
確認する方法
見た目だけで判定するのは難しいため、Unicode のコードポイントを確認するのが確実です。
tojihubでは、「見た目が似た別文字チェック」というツールを公開しており、康熙部首を検出可能です。
文字を貼り付けて、検出された文字の詳細を開くと、その文字が通常の漢字なのか、康熙部首なのかを確認できます。